Machine Learning
Als Teilbereich der künstlichen Intelligenz ist das so genannte ‚Machine Learning‘ bekannt. Dieser Artikel enthält folgende Informationen:

Was ist Machine Learning?
Machine Learning ist ein Teilbereich der künstlichen Intelligenz, in dem Algorithmen zur automatisierten Klassifizierung von Objekten genutzt werden. Das Besondere daran ist, dass der Algorithmus über die Zeit mehr über die zu klassifizierenden Objekte lernt und so in seiner Klassifizierung genauer wird – bis er irgendwann so gut darin ist, dass es ihm gelingt, Vorhersagen über zukünftige Objekte zu machen. Er ist im Stande Objekte genauestens zuzuordnen, selbst wenn er sie noch nicht kennt – eine Aufgabe, an der ein Mensch längst scheitern würde.
Neben der Klassifizierung von bekannten Objekttypen kann Machine Learning auch zur Cluster-Erkennung oder Pattern Recognition verwendet werden. Auch beim Reinforcement-Learning zur Prozessoptimierung wird Machine Learning angewandt, um selbst bei Problemen mit unendlichen Lösungen eine maximal effiziente Antwort zu finden.
Wie funktioniert Machine Learning?
Generell funktioniert Machine Learning so, dass ein vorher ausgewählter, programmierter Algorithmus an einem prozentualen Teil des Datensatzes trainiert wird, um anschließend an einem Restprozentsatz getestet zu werden: Auf Basis des Trainingsdatensatzes erkennt der Algorithmus Gemeinsamkeiten im Datensatz zwischen den jeweiligen Gruppen. Anschließend wird am restlichen, ihm unbekannten Datensatz getestet, wie genau es ihm gelingt, die restlichen Daten basierend auf den gelernten Regeln korrekt zuzuordnen oder zu klassifizieren. Da auch bei den Testdaten die Gruppenkennung gegeben ist wird später schlichtweg verglichen, wie oft der Algorithmus in seiner Zuordnung richtig lag.
Da in diesem Falle die Genauigkeit der Angabe vorliegt kann also später einfach verglichen werden, wie oft der Algorithmus die Datensätze korrekt zugeordnet hat. Diese Metrik nennt sich Sensitivität. Die Spezifität stet dem Gegenüber und beschreibt die Wahrscheinlichkeit einer korrekten Ablehnung. Die Verteilung zwischen Trainings- und Testdaten liegt typischerweise bei 80% Trainings-Daten und 20% Testdaten, sofern der Datensatz umfangreich genug ist. Bei kleineren Datensätzen werden auch gerne prozentual größere Testdatensätze verwendet. Ein 2/3 Trainings- vs. 1/3 Testdatensplit gilt hier als Standard. Das Problem eines reduzierten Trainingsdatensets ist, dass der Algorithmus weniger Möglichkeiten hat, über die Stichprobe zu lernen und eher geneigt ist, später im Testmodus Fehler zu machen. Ein größerer Datensatz, der einen höheren Trainingsdatensplit erlaubt, ist daher stets eine sinnvolle Maßnahme. Der Einsatz von Machine Learning für zu kleine Datensätze (<1.000 Samples) sollte genau überlegt werden.
Neben der Datensatzgröße gibt es einen zweiten entscheidenden Faktor, welcher über die Vorhersagegenauigkeit eines Machine Learning-Klassifizierungsalgorithmus entscheidet: Die Qualität der Daten. Einzelne Variablen, die zur Vorhersage eingebunden werden, werden in diesem Kontext als Features bezeichnet. Je besser die Features geeignet sind, um die jeweiligen Gruppen zu beschreiben, desto besser auch die Qualität der Vorhersage.
Einsatzgebiet: Best Practice Machine Learning
Im Folgenden beschreiben wir Ihnen den Einsatz und Fallstricke des Machine Learning am Beispiel eines Handelsgroßkonzerns:
Der CIO eines großen Handelskonzerns möchte für seine Lebensmittelläden ein automatisiertes Abwiege-System einführen, welches durch Bilderkennung automatisch die abzuwiegenden Früchte erkennt. Diese sollen dann mit der eingebauten Waage gleich gewogen werden. Dieses Vorgehen spart den Kunden zukünftig Zeit beim Einkauf, da sie die jeweiligen Produktnummern nicht mehr heraussuchen müssen. Der CIO beauftragt das neugegründete Data-Team damit, eine effiziente Lösung zu finden.
In einem ersten Test versucht das Data Team zunächst zwischen Äpfeln und Zitronen zu unterscheiden. Hierfür wird ein Datensatz mit 90 Äpfeln und 10 Zitronen erstellt, in dem das Gewicht und die Höhe der jeweiligen Früchte eingetragen wird. Zudem werden Fotos hinterlegt, welche an den Datensatz geknüpft werden: Somit wird jedem Apfel und jeder Zitrone ein Foto zugewiesen. Zudem werden die Höhe und Gewicht einer jeden Frucht bestimmt und dem jeweiligen Foto zugeordnet. Abschließend wird bei den Äpfeln die Farbe “Rot” und bei den Zitronen die Farbe “Gelb” eingetragen. Somit verfügt man nun über einen Datensatz, welcher aus drei Features besteht: Höhe, Gewicht und Farbe der Frucht. Manuell ergänzt wird der Fruchtname, welcher gebraucht wird, um später zu sehen, wie oft der Algorithmus korrekt die Frucht erkannt hat. Der Datensatz sieht final exemplarisch so aus:

Das Data-Team ist zufrieden mit dem Datensatz und wählt basierend auf einer Recherche einen SGD-Klassifizierungsalgorithmus, bei dem man zwei Zielgruppen festlegt: Äpfel und Zitronen. Der Datensatz wird in 80% Trainingsdaten zu 20% Testdaten gesplittet. Der SGD-Algorithmus lernt also an 80 zufälligen Früchten aus dem Datensatz zwischen Äpfeln und Zitronen zu unterscheiden. Später soll er die restlichen 20 Früchte selbstständig korrekt erkennen, hierbei wird der Objektname verborgen.
Der CIO freut sich und lässt die Daten mittels Algorithmus auswerten, doch mit den Resultaten ist er keinesfalls zufrieden: Es wurden lediglich 12 von 18 Äpfeln korrekt identifiziert und nur eine von zwei Zitronen. Damit beträgt die Gesamtsensitivität 65%, bei den Zitronen sind es sogar nur 50%.
Massiv enttäuscht will der CIO das Thema zur Seite legen, doch das Data Team gibt nicht auf und findet einige Fehler in der Zuordnung, die sie gleich mit einem roten X markieren:

Schnell stellt das Team fest, dass beispielsweise ein gelber Apfel als Zitrone und eine aufrecht fotografierte Zitrone als Apfel deklariert wurde. Bei näherer Betrachtung lassen sich weitere Erkenntnisse gewinnen:
- Der Testdatensatz enthielt lediglich zwei Zitronen, von denen eine fälschlicherweise als Apfel deklariert wurde. So sieht ein Prozentsatz von 50% schlecht aus, ein einzelner Fehler hingegen ist vertretbar. Die Divise hier ist: Der Datensatz braucht deutlich mehr als 10 Zitronen um eine dauerhaft präzise Vorhersagewahrscheinlichkeit zu generieren. Die Verteilung zwischen Test- und Trainingsdaten ist zufällig. Dass also nur zwei Zitronen im Testdatensatz landen, ist unglücklich und…
- …durch einen größeren Testdatensatz zu vermeiden. Bei einem generell kleinen Datensatz, welcher nur ein Testdatenset von lediglich 20 Objekten übriglässt, muss die Aufteilung von Test- und Trainingsdaten angepasst werden: Hier wäre also eine Verteilung von 2/3 Trainings- und 1/3 Testdaten ein erster Ansatz, der womöglich helfen könnte. 13 von 20 erkannten Früchten ist kein schlechtes Ergebnis, welches vor Allem von Ausreißern getrieben zu sein scheint.
- Nicht alle Äpfel sind rot: Das Data Team sollte eher dem Bilderkennungsalgorithmus die Farbgebung überlassen, oder die Farbe in ihrer aktuellen Form als Feature gänzlich weglassen, da eine Abweichung in der erkannten Farbe und den hinterlegten Daten den Algorithmus in die Irre führt: So nimmt dieser an, dass ein jeder Apfel rot sein müsse, was dazu führt, dass er gelbe Äpfel als Zitronen deklariert. Auch grüne Äpfel würden so womöglich als Zitronen enden. Dieses Beispiel zeigt, dass Dataautomation gerade im bildgebenden Bereich ein sehr hilfreiches Tool ist. Falls der Einsatz nicht möglich sein sollte, sollte darüber nachgedacht werden, dass manche Features eventuell schlicht nicht dienlich sind. Zur Feature-Selektion gibt es einige wichtige Kennzahlen, die ein jeder Algorithmus automatisch mitliefert, welche erlauben unnötige Features aus den Berechnungen zu entfernen. So verbessert sich die Vorhersagegenauigkeit ungemein.
- Auf dem Foto sehen wir schnell, dass Höhe allein kein gutes Feature ist: Es gibt kleine Äpfel und große Zitronen. Hier sollte mindestens noch die Fruchtbreite erfasst werden. Doch noch wichtiger ist, dass es einheitlich sein sollte: Jede Frucht sollte liegend gemessen werden und nicht, wie bei den Fotos der Zitronen zu sehen ist, einige Früchte stehend und einige liegend. Dies ist ein Beispiel von schlechter Datenqualität, welche zu inkonsistenten Daten führt und eine gute Klassifizierung behindert.
- Auch das Gewicht ist zweifelhaft: Äpfel wiegen allgemein mehr als Zitronen – ungefähr 150g bis 250g je Apfel gegenüber 80g bis 150g je Zitrone. Doch gerade bei kleineren Apfelsorten gibt es Ausreißer. Hier wäre es eventuell sinnvoll nicht nur nach Äpfeln, sondern nach Apfelsorten zu klassifizieren.
- Basierend darauf könnte ein Bilderkennungsalgorithmus eines der wichtigsten optischen Features überhaupt bestimmen: Die Form der Frucht bzw. deren Oberflächenbeschaffenheit. Zudem könnte beispielsweise auch das Vorhandensein eines Stiels erkannt werden, was die Unterscheidung von Zitronen und Äpfeln noch eindeutiger macht. So spart man sich zusätzliches Messen und ist weniger an die Position der Frucht gebunden.
Wir sehen also schnell, dass bei der Auswahl von Machine Learning-Tools zunächst die Datenqualität und Datenquantität gewährleistet sein muss. Machine Learning auf unzureichende oder ungeeignete Datensätze anzuwenden ist nicht zielführend und verbrennt unnötig Ressourcen! Unsere Experten beraten sie diesbezüglich gerne.
Welche Machine-Learning-Lösungen gibt es?
Maschinelles Lernen ist eine komplexe Folge von Abläufen, die vorher festgelegt werden und wohl überlegt angesetzt sein sollten. Ein zu Datensatz und Fragestellung unpassender Algorithmus würde womöglich funktionieren, allerdings würde er die gewünschte Fragestellung nicht maximal effizient beantworten können. Daher ist die wichtigste Frage in diesem Kontext: Wie ist der Datensatz beschaffen?
Dieser Frage folgt gleich die Nächste: Wie lautet die Fragestellung? Aus den Antworten dieser beiden Fragen ergibt sich der gewünschte Algorithmus und damit auch das mögliche Antwortpotenzial. Wir haben die gängigsten Machine Learning-Algorithmen basierend auf Datenart und Fragestellung im folgenden Flowchart zusammengefasst:
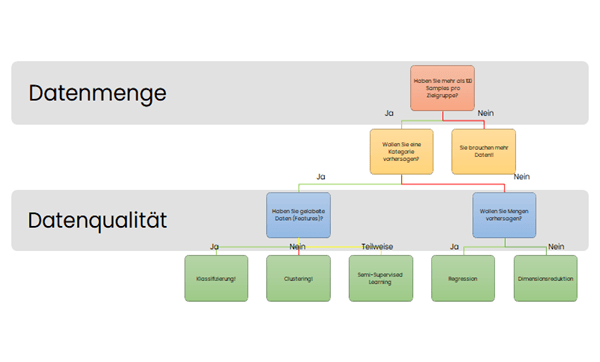
Beispiele: Welche Arten von Machine Learning gibt es?
Insgesamt unterscheidet man vier unterschiedliche Machine Learning-Arten, die je nach Reifegrad und Datensatz Verwendung finden.
Die beiden häufigsten Machine Learning-Arten sind das Supervised Learning und das Unsupervised Learning, die jeweils unterschiedlichen Zwecken dienen. So ist das Supervised Learning vor allem ein Klassifizierungs-Algorithmus, welcher bestehende Daten bestehenden Gruppen zuordnen soll. Ein Beispiel wäre hier der o.g. Fall von Bauer Klein. Ein Unsupervised Learning-Algorithmus hingegen arbeitet mit Daten, die keine Labels haben und soll diese vor Allem auf Gemeinsamkeiten hin gruppieren. Ein Beispiel hierfür wäre ein Customer Segmentation: Man versucht hierbei herauszufinden, wieviele und welche Typen von Kunden es gibt, ohne vorher Annahmen darüber zu machen. Daher ist das Unsupervised Learning auch per se explorativer als das Supervised Learning und hat auch entsprechend andere Anwendungsfelder. Die folgende Grafik fasst die Unterschiede und Gemeinsamkeiten kurz zusammen:
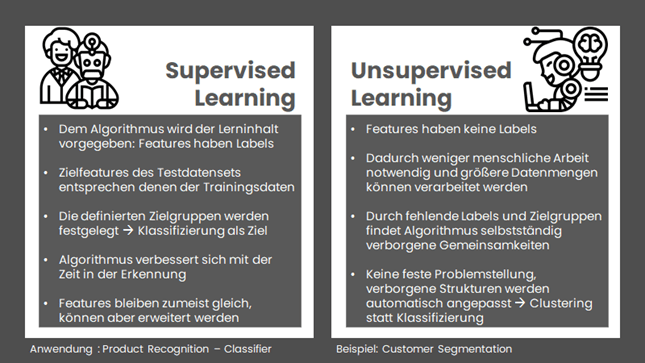
Wir sehen also, dass sich die Ansätze nicht nur in der Anwendung, sondern auch in der Fragestellung fundamental unterscheiden und nicht jeder Datensatz für jeden Machine Learning Algorithmus gleichermaßen geeignet ist.
Zwei weitere Typen des Machine Learning sind das Semisupervised Learning und das Reinforcement Learning.

Dabei vereint das Semisupervised Learning die Vorteile beider vorheriger Welten: Es ist im Stande unbekannte Daten zu clustern, also nach Gemeinsamkeiten zu gruppieren und anschließend mit bestehenden Datensätzen zu vergleichen. Ein Beispiel hierfür ist die Erkennung von Handschriften, die zunächst die Buchstaben auf Gemeinsamkeiten hin untersucht und entsprechend entscheidet um welche Buchstaben es sich handelt um diese dann im zweiten Schritt den bestehenden Textbausteinen zuzuordnen und so zu klassifizieren.
Beim Reinforcement Learning geht es mehr um eine Optimierung, da meistens mehrere Lösungen möglich sind, aber noch unklar ist, welche maximal effizient ist. Das Reinforcement-Learning vertraut also auf einen Interpreter, welches ein Zusatzprogramm ist, welches den vorgeschlagenen Lösungsansatz des Algorithmus prüft und anschließend für gut oder schlecht empfindet, indem er ihn mit bestehenden Lösungen vergleicht. Hier wird also zwischen bestehenden Alternativen verglichen und zielführendere Methoden werden verstärkt (also als Ansatz für Wiederholungen empfunden) und nicht-zielführende Methoden werden abgewertet und als weniger Sinnvoll klassifiziert. Eine mögliche Anwendung hierfür sind Routenfindungsprogramme, wo es quasi unendlich viele Wege zum Erfolg gibt und lediglich der effizienteste (basierend auf bestimmten Kriterien, beispielsweise der kürzeste oder der günstigste Weg) soll gefunden und präsentiert werden. Dabei schlägt der Algorithmus die Lösung vor und der Interpreter schlägt Verbesserungen basierend auf den limitierenden Kriterien vor.
Machine Learning im Business-Kontext
Maschinelles Lernen (Machine Learning) bedeutet, dass man bereits Vorhersagen über das Kundenverhalten treffen kann, bevor dies wirklich eintritt. So etwas funktioniert beispielsweise in den Feldern von Churn, in dem aus den Daten vorher gechurnter Kunden ein Modell geschaffen wird, welches den Churn für aktuelle Kunden vorhersagen kann, da es nuancierte Veränderungen erfasst, die einem jeden Anwender verwehrt geblieben wären: Letztendlich wird also klassifiziert, ob ein Kunde churngefährdet ist. Der Business-Mehrwert liegt hier beispielsweise für Bank- oder Telekommunikationsanbieter, da diese so entscheiden können, wann sie konkret intervenieren wollen.
Ein weiteres Beispiel wäre Fraud-Detection: Hier muss basierend auf Kundenverhalten ebenfalls entschieden werden, ob das Verhalten eines bestimmten Kunden auf Fraud hindeutet oder beispielsweise lediglich ungewöhnlich ist. Jedenfalls wäre auch hier eine klare Klassifizierung möglich, die dann gezielt erlaubt auffällige Accounts individuell zu beobachten – dieses für Banken und Versicherungen extrem wichtige Anwendungsfeld spart so nicht nur Ressourcen, sondern beschützt auch sowohl das Unternehmen als auch andere Kunden vor überfälligem, illegalem Verhalten.
Es zeigt sich also, dass wir viel Mehrwert mit Machine Learning kreieren können und nebenbei menschliche Fehler vermeiden beziehungsweise Umstände aufzeigen, die sonst unentdeckt bleiben müssten.
Welche Machine Learning-Lösung für ihr Unternehmen richtig ist ist also nicht so einfach, doch wir helfen dank unseres großen, erfahrenen Data Science-Teams gerne weiter.