Data Lakehouse
Ein Cloud Data Lakehouse ist eine moderne Datenarchitektur, die die Vorteile von Data Lakes und Data Warehouses kombiniert, um eine flexible und skalierbare Lösung für die Speicherung und Analyse von Daten zu bieten. Diese Architektur ermöglicht es Unternehmen, sowohl strukturierte als auch unstrukturierte Daten an einem zentralen Ort zu speichern und so eine einheitliche Datenplattform zu schaffen, die für verschiedene Analysezwecke genutzt werden kann.
Hier ein grober Überblick des Inhalts:
- Definition: Was ist ein Cloud Data Lakehouse?
- Architektur von Data Lakehouses
- Was sind die Ziele eines Cloud Data Lakehouse?
- Was sind die Herausforderungen eines Cloud Data Lakehouse?
- Welche Arten von Cloud Data Lakehouses gibt es?
- Wie wird ein Cloud Data Lakehouse implementiert?
- Vorteile eines Cloud Data Lakehouse
- Warum kann CINTELLIC bei der Implementierung eines Data Lakehouses unterstützen?

Definition: Was ist ein Data Lakehouse?
Ein Cloud Data Lakehouse vereint die Flexibilität von Data Lakes mit den strukturierten Analysefähigkeiten eines Data Warehouses. Es baut auf einer Data-Lake-Infrastruktur auf und erweitert diese um zusätzliche Funktionen, die es ermöglichen, sowohl strukturierte Daten in Data Marts oder Data-Warehouse-Tabellen als auch unstrukturierte Daten zu verarbeiten und zu speichern. Insbesondere eignet sich ein Cloud Data Lakehouse gut, um große Datenmengen effizient zu speichern und zu verarbeiten – Big Data. Es ermöglicht die Durchführung komplexer Datenanalysen und unterstützt sowohl Business Intelligence (BI) als auch fortgeschrittene Analysemethoden wie maschinelles Lernen (ML) und künstliche Intelligenz (KI). Zudem bietet es kostengünstigen Speicher für umfangreiche Datenmengen und ist damit ideal für Unternehmen, die ihre Datenstrategien skalieren möchten.
Architektur von Data Lakehouses
Die Architektur von Cloud Data Lakehouses verbindet die Flexibilität und Skalierbarkeit von Data Lakes mit den strukturierten Datenverwaltungs- und Analysefunktionen traditioneller Data Warehouses. Diese Architektur ist in Schichten organisiert und bietet somit einen strukturierten Ablauf.
In der Empfangsschicht werden Daten aus verschiedenen Quellen gesammelt, gegebenenfalls gefiltert und/oder vorverarbeitet und schließlich in das Data Lakehouse geladen. Die nächste Ebene ist die Speicherebene, die eine kostengünstige Speicherung bietet und die Handhabung großer und vielfältiger Datenmengen ermöglicht. So stellt beispielsweise die Speicherung von Daten in Rohform kein Hindernis dar, da eine folgende Verarbeitungsebene mehrere Schichten umfasst:
- Bronze-Layer, in dem Rohdaten unverändert aus den Quellen importiert werden.
- Silver-Layer, in dem die Daten bereinigt und organisiert sowie anschließend für einfache BI-Anwendungen bereitgestellt werden.
- Gold-Layer, der für strukturierte Daten optimiert ist und für klassische BI- und Reporting-Anwendungen genutzt wird. Ein wesentliches Merkmal ist die Integration einer leistungsstarken SQL-Engine, die es ermöglicht, direkt auf die Daten im Data Lake zuzugreifen und komplexe Abfragen durchzuführen.
Alle Anwendungen und Operationen auf den Daten werden in einer Metadatenebene gespeichert, die Informationen über die Datenstruktur, -herkunft und -verarbeitung enthält. Diese Metadatenebene ermöglicht eine effiziente Verwaltung, Nachverfolgung und Nutzung der Daten, wodurch die Konsistenz, Integrität und Auffindbarkeit der Daten für verschiedene Analysezwecke gewährleistet wird.
Letztlich gelangen die Daten in die Verwendungsebene, wo sie einsatzbereit sind. Diese Architektur eignet sich hervorragend für fortgeschrittene Analysen und KI-Anwendungen, da sie die Echtzeitanalyse sowohl strukturierter als auch unstrukturierter Daten ermöglicht. Dies ist besonders attraktiv für Data Scientists, Analysten und Stakeholder, da tiefere Einblicke und fundierte Entscheidungen ermöglicht werden. Darüber hinaus bietet die Architektur eine optimierte Datenverwaltung, die höchste Compliance- und Sicherheitsanforderungen erfüllt – ein entscheidender Vorteil für Unternehmen mit strengen Vorgaben in Bezug auf Datensicherheit und Governance.

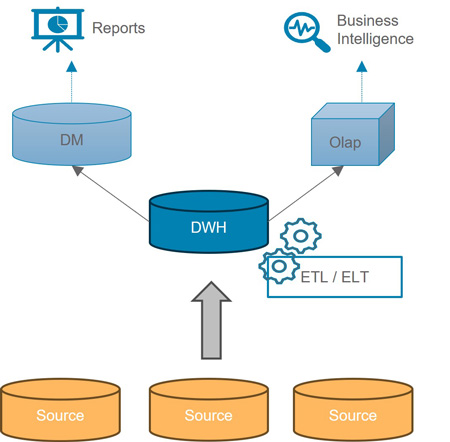
Data Lakehouse vs Data Lake vs Data Warehouse
Die Speicherarchitektur von Data Lakes ist schnell und anpassungsfähig, da hier „Schema on read“ verwendet wird, wodurch die Datenstruktur vorher nicht definiert sein muss. Data Lakes unterstützen alle Arten von Daten, können aber schnell unübersichtlich werden und sind nicht für komplexe Abfragen optimiert. Häufig werden sie für analytische und maschinelle Lernzwecke genutzt.
Im Gegensatz dazu ist die Speicherung in Data Warehouses (DWH) aufwendiger, da die Datenstruktur zuvor festgelegt sein muss (Schema on write). Die Daten werden mithilfe sogenannter Extract-Transform-Load (ETL)-Pipelines von Schicht zu Schicht transportiert, was zu erheblichen Vorteilen für die Leistungsfähigkeit und Komplexität der Abfragen führt. Gleichzeitig wird eine hohe Data Governance und Datenqualität sichergestellt. Allerdings sind die Kosten dafür höher, und die Unterstützung von semi- und unstrukturierten Daten ist begrenzt, was in der heutigen Datenlandschaft einen Nachteil darstellt. Letztendlich sind DWHs nicht für Abfragen auf neu eintreffende Daten geeignet.
Beschreibung:
- Als Speicher für strukturierte, semistrukturierte und unstrukturierte Daten wird ein Spicher verwendet
- Zur Berechnung der Daten wird auf leistungsstarke Compute-Engines zurückgegriffen, die in Echtzeit die Daten aus dem Lake zugreifen und dabei das Prinzip „Schema-on-Read“ verwenden
- Als Ergänzung für strukturierte Daten und Dashboards wird oft ein DWH / DataMart verwendet oder die Verwendung eines weiteren Daten-Analyse-Tools
Vorteile:
+ Gut geeignet für „Big Data“
+ Preiswerter Speicher
+ Verarbeitung von halbstrukturierten und unstrukturierten Daten
+ Lösung für erweiterte Analyse- und KI-Anwendungen
Nachteile:
– Mangel an Metadatenmanagement und damit Kontrolle über die Daten -> Gefahr eines „Datensumpfs“
– Hoher Aufwand für Synchronisation und Wartung zweier Systeme (DWH + Data Lake)
– Daten Sicherheit
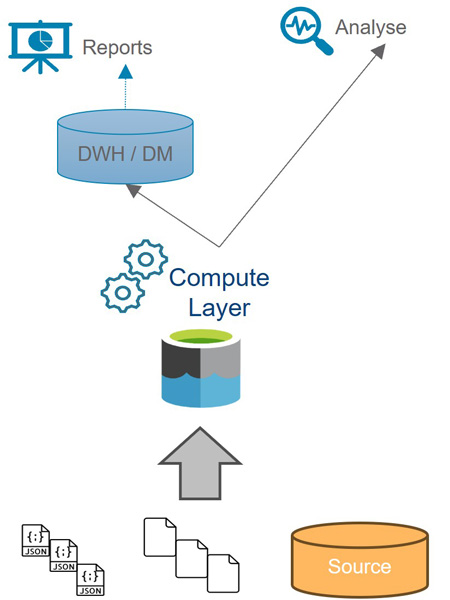
Im Gegensatz dazu ist die Speicherung in Data Warehouses (DWH) aufwendiger, da die Datenstruktur zuvor festgelegt sein muss (Schema on write), sodass die Daten mithilfe sogenannter Extract-Transform-Load-(ETL)-Pipelines von Schicht zu Schicht transportiert werden. Dadurch ergeben sich erhebliche Vorteile für die Leistung und Komplexität der Abfragen. Gleichzeitig kann auch für Data Governance und Datenqualität gesorgt werden. Allerdings sind die Kosten dafür höher, und die Unterstützung von semi- und unstrukturierten Daten ist begrenzt, was in der heutigen Datenlandschaft einen Nachteil darstellt. Letztendlich sind DWHs nicht für Abfragen auf neu eintreffende Daten geeignet.
Beschreibung:
- Relationale DB als Speicher mit einem ETL-Tool
- Prinzip: Schema-on-Write
- BI-Frontend, normalerweise ein Data Mart als direkte Datenbank
- Erweiterte Analysen, normalerweise über SQL-Abfrage an die Datenbank oder die Verwendung eines weiteren Daten-Analyse-Tools
Vorteile:
+ Standardverfahren zur dispositiven Datenhaltung strukturierter Daten
+ Ausgefeiltes Metadatenmanagement durch die angenommene Datenmodellierung
+ Gemeinsame Datenhaltung für BI-Frontend
Nachteile:
– Teure Speicherung
– Langsame Entwicklung durch „Schema-on-Write“
– Fehlende Möglichkeiten zur Verarbeitung semistrukturierter und unstrukturierter Daten− Unflexibel für Ad-hoc-Auswertungen, wenn Daten nicht im DWH verfügbar sind
– Unzureichende Möglichkeiten für erweiterte Analysen
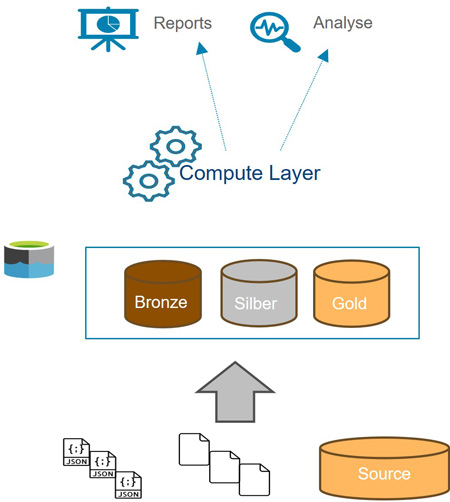
Data Lakehouses vereinen letztlich die Vorteile der beiden zuvor erläuterten Konzepte.
Beschreibung:
- Setzt auf die Data Lake Infrastruktur auf
- Stellt einen berechneten Data Marten / DWH-Tabellen direkt im Date Lake zur Verfügung
Vorteile:
+ Gut geeignet für „Big Data“
+ Preiswerter Speicher
+ Verarbeitung von semistrukturierten und unstrukturierten Daten
+ Lösung für Advanced Analytics und KI-Anwendungen
+ Dank eines Gold-Layers auch für klassische BI-Anwendungen geeignet
+ SQL-Engine vorhanden und produktiv nutzbar
+ Data Governance
Nachteile:
– Basis Anwendungen i.d.R. nur bei Public-Cloud Anbieter verfügbar
– Hohe Kosten bei falscher Compute-Infrastruktur Auswahl
– Nicht immer die effizienteste Methode
Übersicht zwischen den Konzepten
| Feature | Data Lakehouse | Data Lake | Data Warehouse |
| Use Cases | BI, ML, Analytics | ML, Data Exploration, Big Data Analytics | BI, Reporting & Analytics |
| Schema Flexibilität | Flexibles Schema, sowie on-Read & on-Write Schema | Flexibles Schema, unterstützt on-Read Schema | Starres Schema, unterstützt on-Write Schema |
| Datenspeicherung | Kosten-effiziente Cloud-Objektspeicherung mit optimierten Formaten | Günstige Cloud-Objektspeicherung | Teurere, hochleistungsfähige Speicherung (SSD, Datenbank-Speicherung |
| Verarbeitungskapazitäten | Unterstützt sowohl Batch- als auch Echtzeit-Verarbeitung | Hauptsächlich Batch-Verarbeitung | Optimiert für SQL-Abfragen und OLAP (Online Analytical Processing) |
| Unterstützte Datentypen | Strukturierte als auch unstrukturierte Daten | Hauptsächlich unstrukturierte und semi-strukturierte Daten | Hauptsächlich strukturierte Daten |
| Leistungsoptimierung | Teil Optimiert durch die Kombinierung von Indexierung und Caching für schnelle Abfragen | Begrenzte Optimierung, Rohdatenspeicherung | Hoch optimiert für Leistung, Indexierung, Partitionierung |
| Data Governance und Sicherheit | Hohe Sicherheit mit einheitlicher Governance für verschiedene Datentypen | Grundlegende Sicherheit (fehlenden feingranulare Zugriffskontrollen) | Starke Sicherheitsfunktionen mit detaillierter Zugriffskontrolle |
| Kosteneffizienz | Kostengünstiger durch einheitliche Speicherung und Verarbeitung | Verarbeitung erzeugt höher Kosten und Speicherung niedrige Kosten | Höhere Kosten durch optimierte Speicherung und Rechenleistung |
Was sind die Ziele eines Cloud Data Lakehouse?
Die Hauptziele eines Cloud Data Lakehouses sind die Verbesserung der Datenverfügbarkeit, die Beschleunigung von Analyseprozessen und die Schaffung einer einheitlichen Datenplattform, die für verschiedenste Anwendungsfälle genutzt werden kann. Es ermöglicht Unternehmen, schneller auf Marktveränderungen zu reagieren, fundierte Entscheidungen zu treffen und Innovationspotenziale durch die Nutzung fortschrittlicher Analysetools zu erschließen.
Was sind die Herausforderungen eines Cloud Data Lakehouse?
Trotz seiner Vorteile bringt ein Cloud Data Lakehouse auch Herausforderungen mit sich. Dazu gehören die Abhängigkeit von Cloud-Anbietern, hohe Kosten bei falscher Infrastrukturwahl und die Notwendigkeit, eine effiziente Datenverwaltung sicherzustellen, um die Leistung zu maximieren. Zudem erfordert die Implementierung oft spezialisierte technische Kenntnisse, um die Infrastruktur optimal zu gestalten und zu betreiben.
Welche Arten von Cloud Data Lakehouses gibt es?
Cloud Data Lakehouses können je nach Anwendungsfall und technischer Implementierung variieren. Einige Beispiele sind plattformgebundene Lakehouses, die eng mit bestimmten Cloud-Anbietern wie Azure, AWS oder Google Cloud integriert sind, sowie plattformunabhängige Lösungen, die auf Open-Source-Technologien basieren und größere Flexibilität bieten.
Wie wird ein Cloud Data Lakehouse implementiert?
Bei der Einführung eines Cloud Data Lakehouses werden Data Lake-Technologien mit herkömmlichen Data Warehouse-Funktionen integriert. Dafür ist es notwendig, passende Cloud-Plattformen zu planen und auszuwählen, eine zuverlässige Dateninfrastruktur zu entwickeln (z. B. ETL/ELT-Prozesse zu definieren und umzusetzen) sowie auf skalierbare Speicherlösungen und Verarbeitungs-Engines zu setzen. Letztlich sollen Sicherheits- und Governance-Mechanismen eingeführt werden, um gewährleisten zu können, dass Vorschriften geschützt und eingehalten werden. Nachdem alles einsatzbereit ist, sind Überwachung und Optimierung von großer Bedeutung, um eine maßgeschneiderte Lösung zu finden.
Wir unterstützen Sie gerne beim Aufbau eines Data Lakehouses.
Vorteile eines Cloud Data Lakehouses
-

Ideal für Big Data
Perfekt für die Verarbeitung umfangreicher Datenmengen geeignet.
-
Kostengünstiger Speicher
Nutzt preiswerte Speicherlösungen, was die Gesamtkosten senkt.
-
Flexible Datenverarbeitung
Unterstützt die Verarbeitung von semistrukturierten und unstrukturierten Daten.
-
Unterstützung für fortgeschrittene Analysen
Bietet Lösungen für Advanced Analytics und KI-Anwendungen.
-
Kompatibilität mit BI-Anwendungen
Dank eines Gold-Layers auch für traditionelle BI-Anwendungen einsetzbar.
-
Produktive SQL-Nutzung
Integrierte SQL-Engine ermöglicht direkte und effiziente Datenabfragen.
-
Starke Data Governance
Stellt sicher, dass Datenrichtlinien und Compliance-Anforderungen erfüllt werden.
Warum kann CINTELLIC bei der Implementierung eines Data Lakehouses unterstützen?
Bei der Erstellung eines Data Lakehouses gibt es viele Herausforderungen und Stolpersteine, die die Qualität des Modells beeinflussen können. Mit seiner langjährigen Erfahrung unterstützt CINTELLIC beim Meistern dieser und begleitet Sie im gesamten Implementierungsprozess, um das bestmögliche Ergebnis zu erreichen. Kontaktieren Sie uns gerne!